
MaxDiff is an approach for obtaining preference/importance scores for multiple items. Although MaxDiff shares much in common with conjoint analysis, it is easier to use and applicable to a wider variety of research situations. MaxDiff is also known as "best-worst scaling".
Research has shown that MaxDiff scores demonstrate greater discrimination among items and between respondents on the items.







MaxDiff is an approach for obtaining preference/importance scores for multiple items (brand preferences, brand images, product features, advertising claims, etc.) using marketing or social survey research.
There are four features of a MaxDiff design that make it such an outstanding tool
Steps to Design a Max Diff Study
At Knowledge Excel, we have the experience to work on various types of Max Diffs like:
Wish to know more about Bandit Max diff. Watch this video
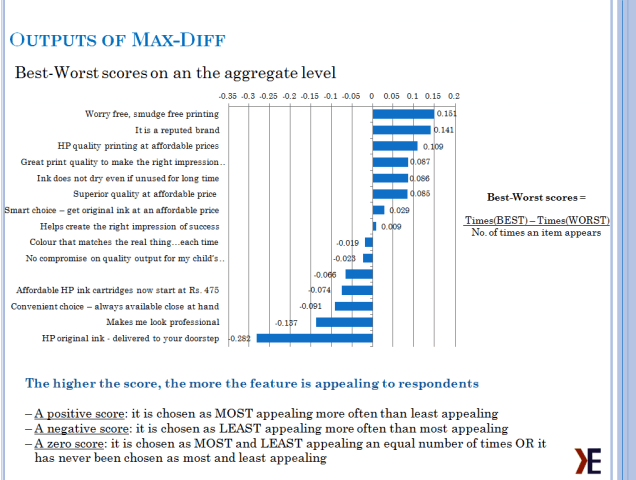
MaxDiff data involve choices: respondents are shown items and asked to choose among them. This kind of data is very useful in marketing and social research applications.
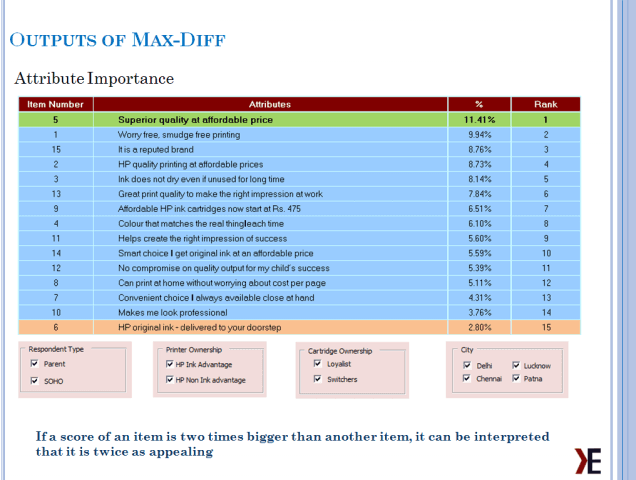
The analysis of this data involves observing the probabilities of choice for the items. These probabilities are represented as customers preference for each item that can be used to rank and/or index these items for relative comparison. Generally it is preferred to index by the highest preferred item, but results can be indexed from average or lowest preferred item as well.
Four types of analysis are offered in the MaxDiff System:
Counting Analysis: Counting analysis takes into account how often each item was available for choice, and how many times it was selected as best or worst.
Individual-Level Score Estimation: MaxDiff uses a sophisticated HB estimation technique to produce scores for each respondent on each item. The HB estimation routine is able to stabilize the estimates for each individual by "borrowing" information from the body of respondents in the same data set.
Aggregate Score Estimation via Logit: Aggregate Logit has been used for more than three decades in the analysis of choice data. It is useful as a top-line diagnostic tool (both to assess the quality of the experimental design and to estimate the average preferences for the sample). Logit can be quite useful for studies in which you are studying very many items and where respondents cannot see each item enough times to support individual-level analysis of scores via HB.
Latent Class Estimation: Latent Class is often used to discover market segments (for use as banner points) from MaxDiff data. Segment membership is reported on the Segment Membership tab of the output.
The simulator is a stand-alone package that allows clients to conduct alternative b what-ifb scenarios. Developed in Excel, a simulator is a powerful analysis tool and the most important deliverable resulting from a max diff project.
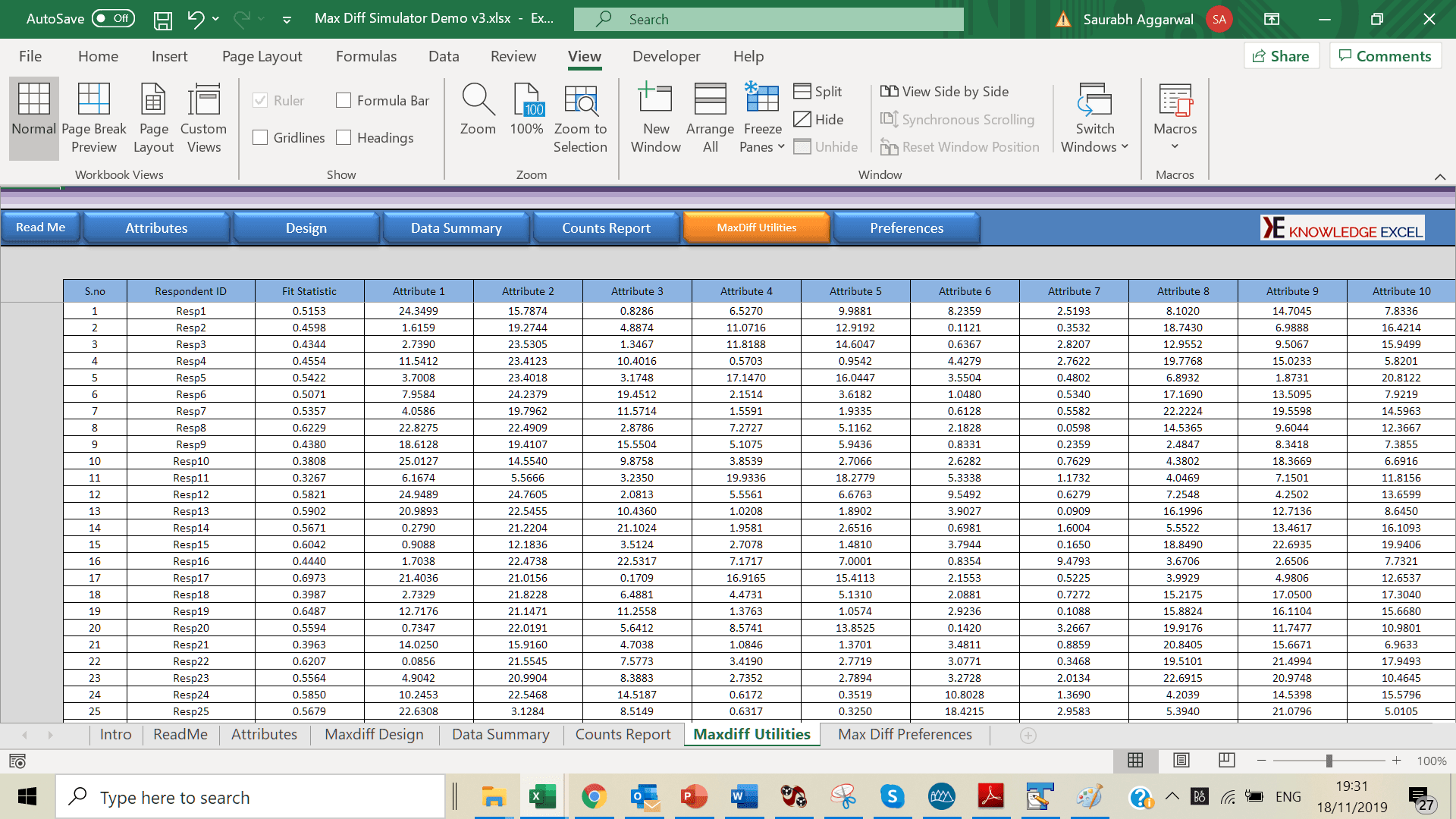
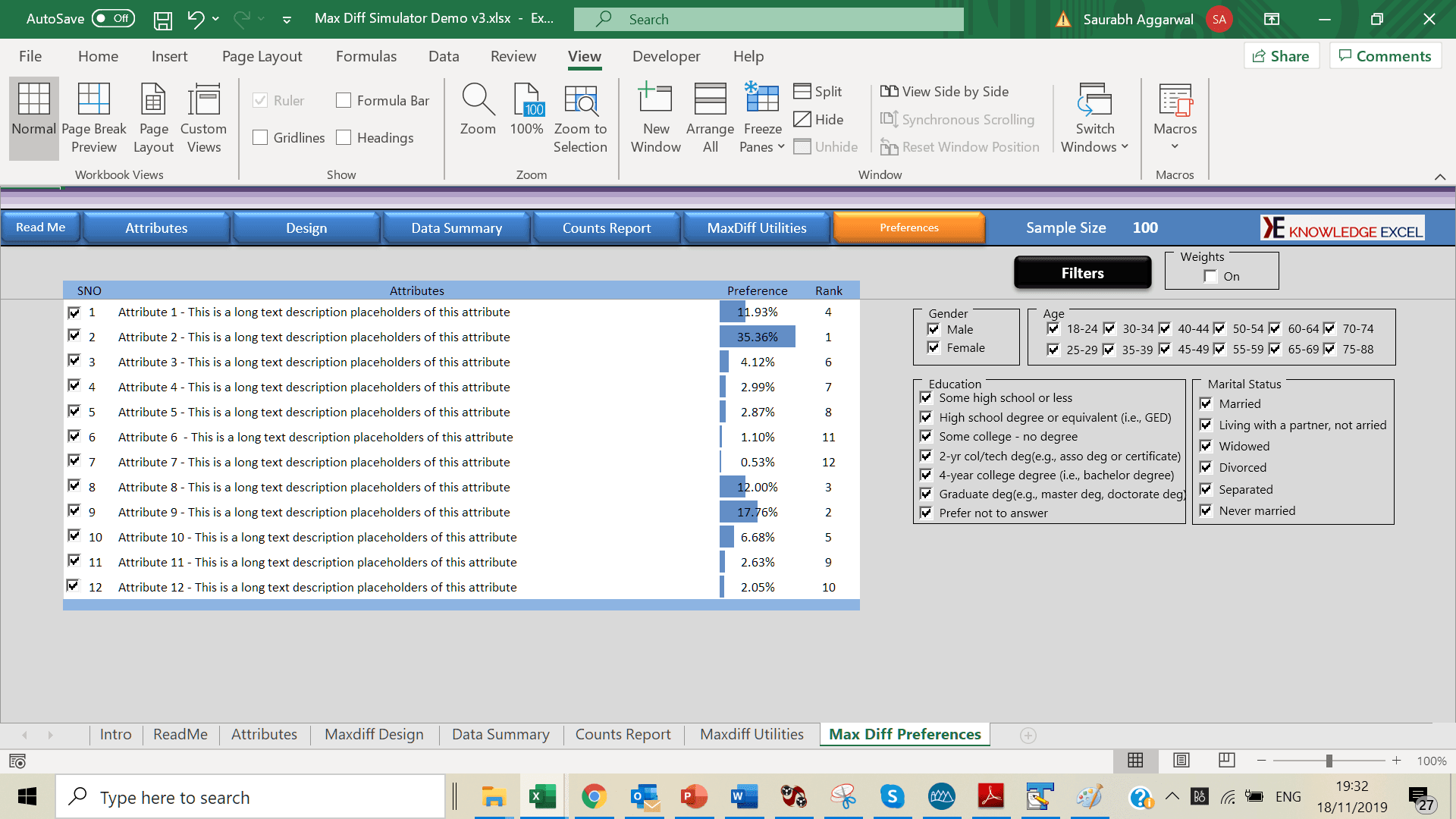
The max diff simulator is an effective tool for computing preference share, counts report, average utilities etc. You can also select which items are to be made available to respondents (as if they were in competition with one another within a marketplace).
Simulators transform the utility data from your max diff study into a tangible tool that you and your end-clients can use. Because it is in Excel, you can easily share it with colleagues and end-clients to maximize use.
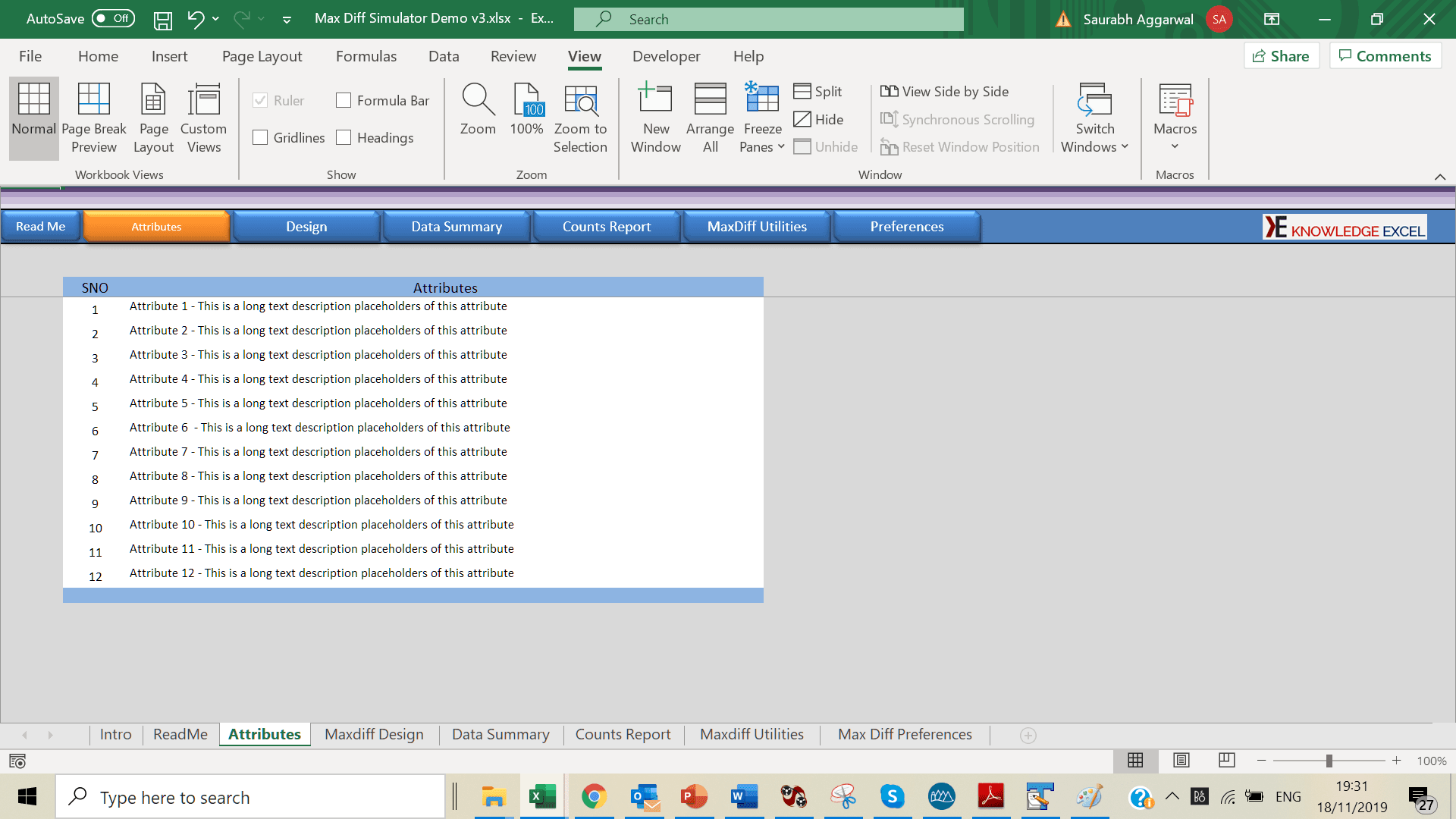
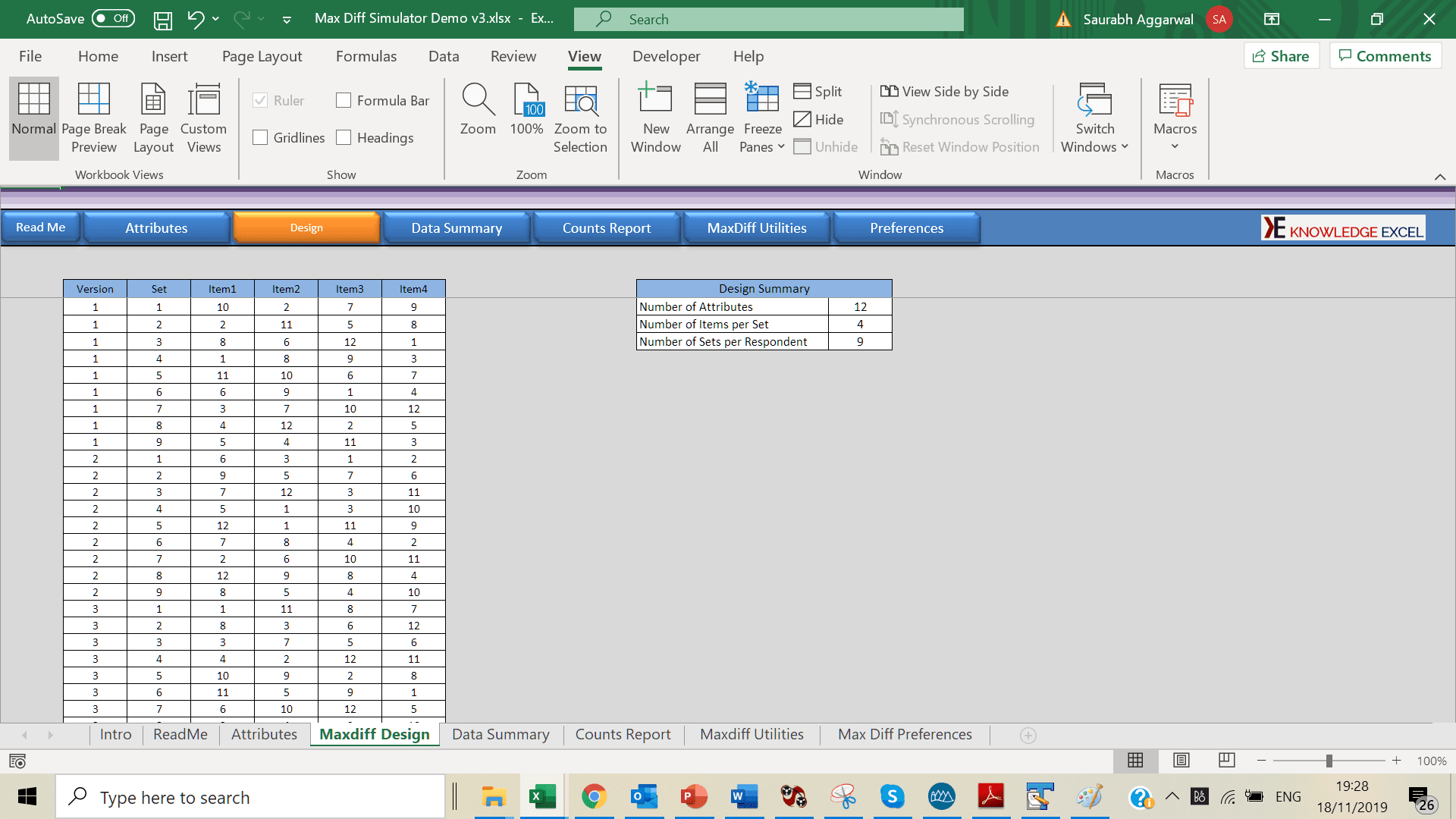
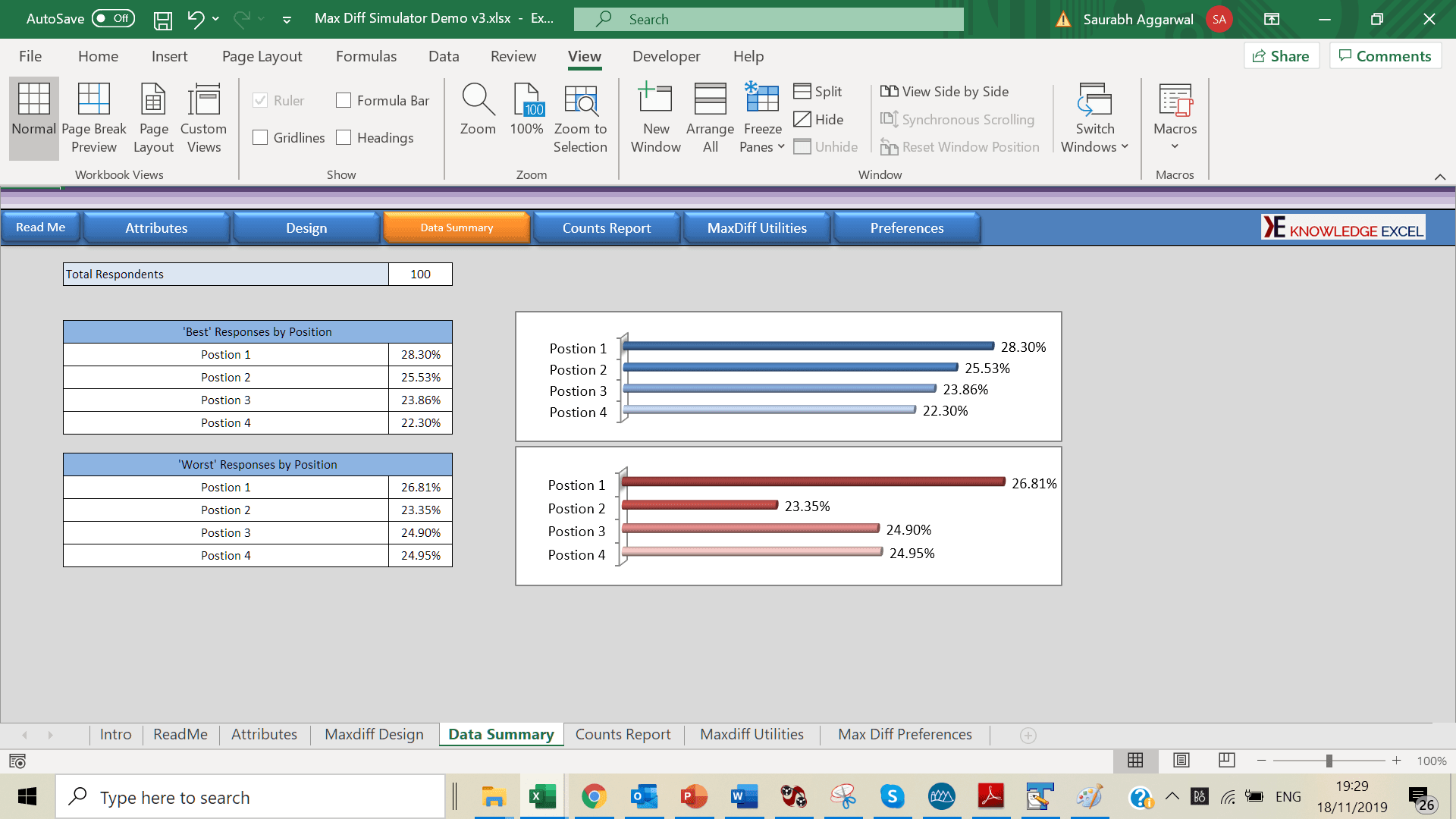
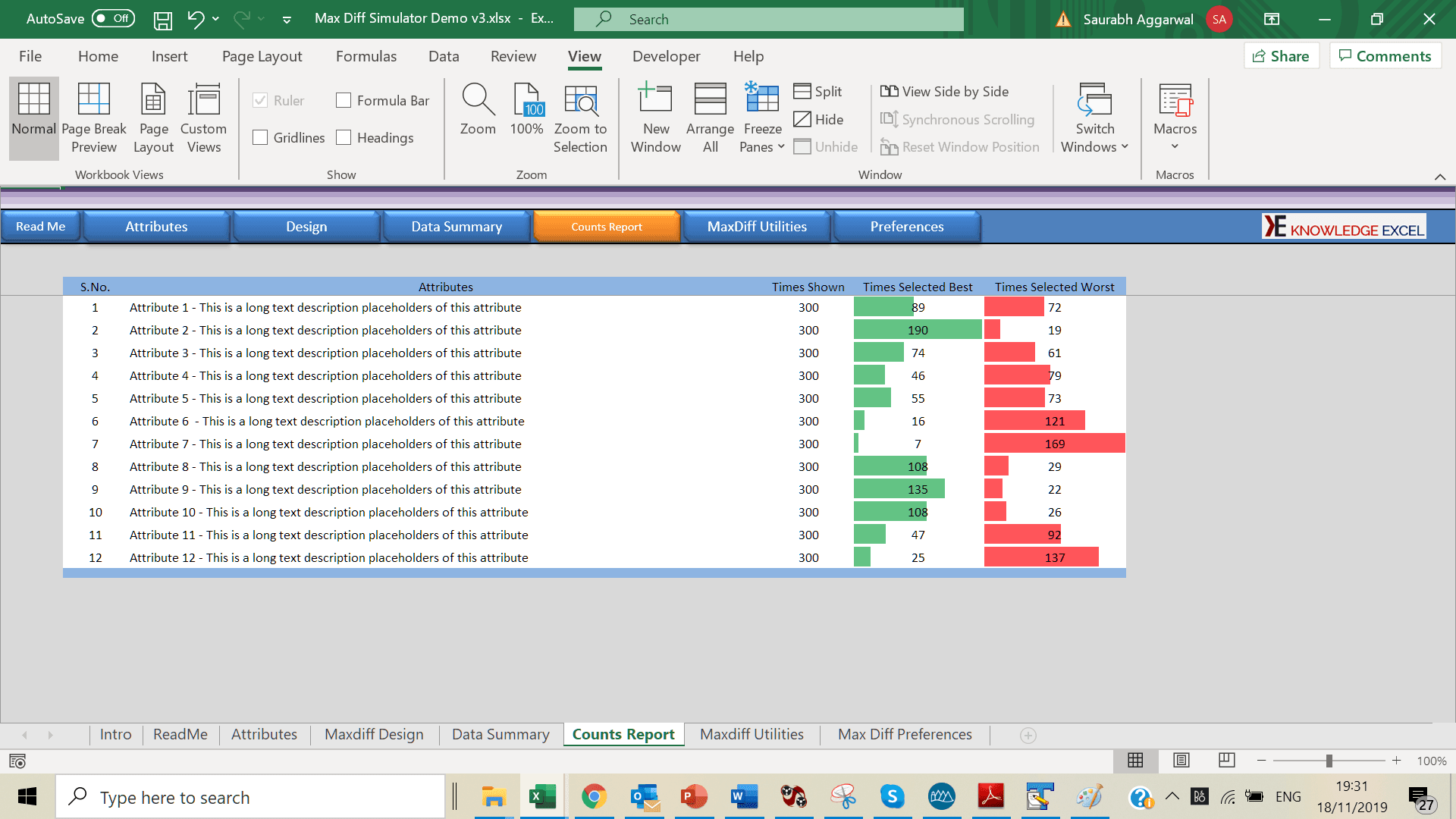
Cloud Based Simulator

Fast Food Chain want to decide the menu option to launch next season.
If you are looking for a reference book on Max Diff, we highly recommend you to read book on Applied MaxDiff written by Keith Chrzan and Bryan K. Orme. For more information click here



